1.1 大数据时代的数据分析流程
传统的数据分析数据量小(做研究一般几万条数据,且以数值型数据为主,别人提供为主),大数据时代数据量明显增加(做研究都在数十万起步,数据类型更加多样,数值型数据,文本数据,甚至图像数据都在涌现,这些数据散布在互联网或线下各处,需要自己想办法获取并处理)。相应地,数据分析的流程更加复杂化,如下图所示:
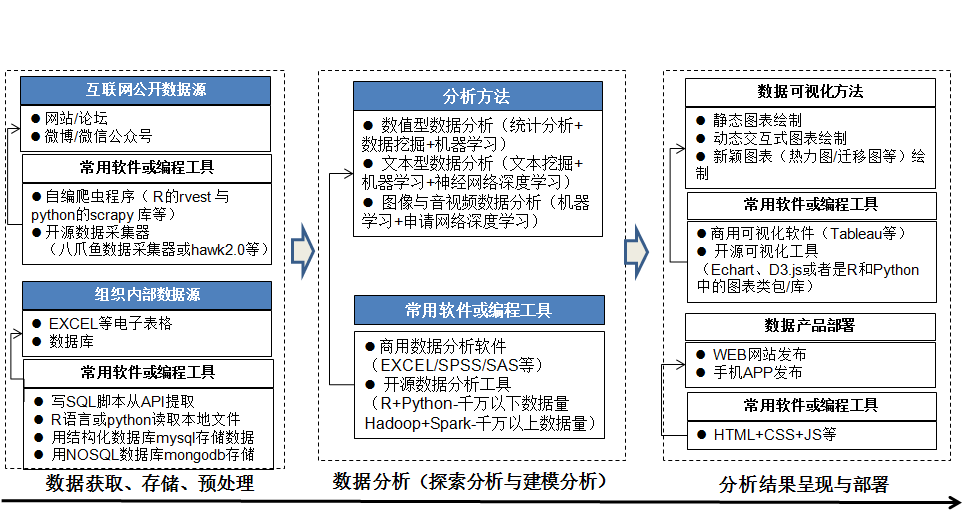
图 1.1: 数据分析流程
接下来本书会从数据分析的全过程对涉及的分析方法、分析软件工具,基本技巧做一初步说明,帮助读者在后续学习过程中,见一树而知其在森林中所处位置,这样心中有结构化的知识体系,不会茫然。
1.1.1 数据获取
大数据时代,数据的来源十分广泛,有从互联网等公开渠道获取,也有从组织内部渠道获取,在方法选择、软件工具选择上有所不同:
互联网上的数据主要用网络爬虫来爬取,简单上手的如八爪鱼采集器(下载网址:www.bazhuayu.cc),这个工具软件比较适合文科学生,不想编程,但又想爬取数据。但它的问题是,免费版爬数据慢,无法同时自定义多个网站的爬取。如果想自由编程、快速爬取,如多线程、自定义多个网站,建议学习python的爬虫相关模块,如bs4、scrapy等。
公司内部的数据,如果是以数据库形式存放,可以写SQL语句读取;或者用R、python的数据库连接包来读取;如果是XLS文件,考虑到存储的数据记录一般都不超过几十万条,建议用R语言直接读取(建议用readxl包)。
一般的建议是:用八爪鱼抓取静态页面类型的中小型网站,编写爬取规则快,数据爬取速度快;如果是含JS页面、AJAX页面等动态页面类型网站或反爬功能强的网站,建议学习python爬虫爬取。R语言中也有爬虫功能的包(如rvest、httr、xml等),但是R的爬虫生态还不够强大,相比于python,R的爬虫比较繁琐。
1.1.2 数据存储
从互联网上爬取来的数据,如果数据量不大(如万条以内),可以以XLS文件的形式存放,以后可以直接在EXCEL中处理。不过仍然建议用R来处理,R中的dplyr、tidyr等包功能强大,数据处理很方便。
如果数据量较大(万条以上)或价值高(今后要复用,且需要对外展示),建议用mysql数据库来存放。原因有二:其一,开源软件,其二,操作较为简便。我们可以用phpadmin来管理mysql,详见案例操作:用phpadmin 管理mysql数据库。
更大的数据,可以TXT或CSV格式存放,可以用R(如果数据量在百万条以上,可以用data.table包的fread函数读取,kaggle比赛的示范代码,一千万行数据记录读取,仅耗时1分钟)或python来读取。
1.1.3 数据预处理
从互联网上获取的数据,一般都是dirty data,要么有缺失值,要么字段不规范等等,不做预处理就着手分析,会印证数据分析的名言:
Garbage in, Garbage out
即便是从组织内部数据库或EXCEL获取的数据也需要检查,确保无误方能进入下一步分析。数据预处理,要根据获得的数据类型采用不同的方法:
数值型数据
读入数据后,先检查数据对象类型,查看字段及记录条数;
检查有无缺失值, 缺失值数据进行处理;
如果是连续型数值数据,检查数据的分布情况,有无异常值,对异常值数据进行处理;
如果是类别数值数据,看有无缺失类别,或类别分布异常情况;
在R语言中,要注意类别数据如果是以字符形式(如地区:BJ-代表北京)表示,要看是因子型还是字符型;
文本型数据
读入数据后,先检查数据对象类型(在R语言里一般list居多),查看字段及记录条数;
检查文本数据有无乱码或异常字符,如有,要用正则表达式处理;
如果读入的文本数据是中文字符,后续要分析的话,需要先做中文分词(在R语言里用jiebaR分词包);
如果读入的文本数据后续要基于词向量(word embeding)分析,还需要用word2vec来对语料文本进行词向量预处理(建议在python里实现,用scikit-learn包里的word2vec);
python中的文本处理一般用nltk包(详细介绍见:http://www.nltk.org/)
这里只是数据处理的简要介绍,详细操作会在本书的后续章节结合实例进行详细介绍。
1.1.4 数据建模分析
作为专业数据分析人员,国内外主流的数据分析工具软件一般用R和python,这两个软件的共性是:
开源软件,第三方包都很多,R有1万个(见CRAN),python有10万个(见pypi), 站在前人肩上前进,不重复造轮子;
有成熟的社区、教程和众多用户;
有很好的IDE和编辑器支撑(R语言一般用Rstudio,python一般用anaconda,外加sublime text)。
不同之处在于:
- R适合研究用,不太适合生产部署;
- python功能更强大,除了数据分析,还可以web开发,自动运维等。
结合二者的特点,它们有不同的分工:我们一般用R做统计分析(如回归分析、面板数据计量分析等)和简单的机器学习模型,另外用R中的ggplot2做图表;用python做数据爬取,做复杂的机器学习模型和深度学习模型,检验和调参,然后部署。
数值型数据的分析:传统的统计分析(如T检验、方差检验、线性回归方程等),用R实现最为方便;数据挖掘和机器学习算法(如分类、聚类、关联规则等)在R语言中分散在多个包中实现,而在python中,则是统一由scikit-learn包实现,十分方便,建议先从R语言学习起步,之后转到python中实现。神经网络和深度学习(即深度神经网络),建议用python来实现。