1.1 数据、信息、知识与智慧
人类对客观事物的认识组成了人类思想的内容,这个认识过程是一个从低级到高级不断发展的过程,而数据(Data)、信息(Information)、知识(Knowledge)与智慧(Wisdom)就是人类认识客观事物过程中的不同产物。
首先通过一个实例,让大家对数据、信息、知识有一个初步的了解:
“数据:37”,外部环境温度的变化,被观测仪器或人的感官感知后,我们用一个数字赋予其特定标识,这就是数据。但是,单看这个数据本身很难给出进一步延伸的含义。如果加上“2015年8月1日北京气温37℃”,这个时候37就有意义了,这时,数据就转换成了信息。进一步地,根据中国气象局多年的气象记录,气温在35℃以上一般称为“高温天气”。高温天气下人们要尽量减少户外运动,在户外时要做好防晒工作,同时要注意多喝水、避暑等,这便是在信息的基础上人们总结出来的知识。如果根据多年的气温变化知识,我们对未来一段时间的气温变化做出预测,形成工作预案,某种程度上,知识就转化为了智慧。
从“数据:37”到“信息:2015年8月1日北京气温37℃”到“知识::2015年8月1日北京高温天气到“智慧:未来1年北京8月气温日趋升高”,反映的是人类对外部客观世界的认识从低级到高级不断螺旋式上升的过程。
在对数据、信息、知识与智慧内涵有了初步感性认识的基础上,表 1.1 将国内外学者针对这四个概念的研究进行了汇总与比较:
| 定义者 | 数据 | 信息 | 知识 | 智慧 |
|---|---|---|---|---|
| Wiig(1999) | 由一系列描述特定情境、环境、挑战或机会的有组织的事实和数据所组成的 | 人或者其他无生命事物所拥有的真理和信念、视角和概念、判断和预期、方法论和技能等 | ||
| Alavi.M and D.E.Leidner(1999) | 原始的 , 除了存在以外没有任何意义 | 经过处理可以利用的数据;回答“谁”、“什么”、“那里”和“什么时候”的问题 | 数据和信息的应用,回答“如何”的问题 | 智慧是一种推测的、非确定性的和非随机的过程 |
| Gene Bellinger,Durval Cas-tro,Anthony Mills(2004) | 一个事实或一个与其它事情无关的事件陈述 | 包含某种类型可能地因果关系的理解 | 这样一种模式,当它再次被描述或被发现时,通常要为它提供一种可预测的更高的层次 | 对更多的基本原理的理解,这种原理包含在知识中,而这种知识本质上是对知识是什么的基础 |
| Nancy.M.Dixon | 一定形式组织起来的数据,即是能够被存储、分析、展示,可以通过语言、图表或数字交流的一组数据 | 特殊背景下,人们在头脑中,将信息与信息在行动中的应用之间所建立的有意义的联系 | ||
| Davenport,T.H.,and L.Prusak(1998) | 一组分散的事实 | 试图改变接受者认识的消息 | 一种由经验、价值、情境化信息、专家见解等构成的流动的混合物,它们可以为评价并整合新经验、新信息提供一个框架 | |
| Vance(1997) | 经过解释能够成为一种结构含义丰富的数据 | 经过证实并被认为具有真实性的信息 | ||
| Maglitta(1995) | 原始的数字和事实 | 经过处理的数据 | 可发挥作用的信息 | |
| 马克·金斯伯格和埃吉特·坝贝尔 | 企业中一系列记录在案的、分散的及客观的事实 | 向企业成员提供的这些数据所代表的前后相关含义 | 同Davenport,T.H.,and L.Prusak,1998 | |
| Quigley and Debons(1999) | 没有回答特定问题的文本 | 回答“when,where,what,who”问题的文本 | 回答“how,why”问题的文本 | |
| MichaelJ.Marquardt | 包括文本、事实、有意义的图像,以及未经解释的数字编码等 | 有前后文联系、有意义的数据 | 体现了信息的本质、原则和经验,它们能够积极地指导任务的执行和管理,进行决策和解决问题 | 包括组织能高效地创造产品、服务和流程的才能和专门知识 |
| H.J.Bajaria | 收集原始数据以便于再利用 | 立刻找回与当前兴趣有关的数据 | 检查以前的成功的方案以适应当前的环境 | 对照当前的经济形势,检验过去行动的有效性 |
| 王德禄 | 反映事物运动状态的原始数字和事实 | 已经排列成有意义的形式的数据 | 经过加工提炼,将很多信息材料的内在联系进行综合分析,从而得出的系统结论 | 激活了的知识,主要表现为收集、加工、应用、传播信息和知识的能力,以及对事物发展的前瞻性看法 |
数据来源:参考 (荆宁宁 and 程俊瑜 2005) 一文整理
综合国内外学者的观点,下面分别对数据、信息、知识与智慧的内涵与相互关系进行说明。
1.1.1 数据的概念及类型
数据(Data)是客观事物的符号表示(Symbolic representation)。反映客观事物状态和状态的变化,一般通过仪器或设备自动感应(如传感器等)或人体感官主动感知,以文本、数字、音频、图形图像、视频等形态呈现。数据是最原始的记录, 通常未被加工解释, 没有其他意义。
国际标准化组织(ISO)将数据定义为“对事实、概念或指令的一种特殊表达形式,它可以用人工或自动化装置进行通信、翻译或处理”。中国的国颁标准(GB5271.1-85)将对数据定义为“事物、概念或指令的一种形式化的表示形式,以适合于人工或自动方式进行通信、解释或处理”。
数据有多种类别划分,说明如下:
- 按照呈现的形态,可以分为:
- 数值数据(数字形态的数据),通常是物理世界数量特征及其变化的映射;
- 文本数据(语言文字形态的数据),通常是人类思想意识及其变化的映射与表征;
- 多媒体数据(如图像、声音、视频等)。
- 按照呈现的状态,可以分为:
- 静态数据(data at rest): 存放在电子表格、关系型数据库中的数据,通常高频读,低频写;
- 动态数据(data in motion):如存放在临时表或内存型数据库中的数据,通常高频读与写。
- 按照存储格式,可以分为:
- 结构化数据(structured data):以二维表格式存放在EXCEL电子表格、MySQL、Oracle、SQL Server等关系型数据库中的数据,可以通过固有键值获取相应信息,数据结构为,以行为单位,一行数据表示一个实体的信息,每一行数据的属性相同;
- 半结构化数据(semi-structured data):以XML或json等格式存储的数据,可以通过灵活的键值调整获取相应信息,且数据的格式不固定,以json格式为例,同一键值下存储的信息可能是数值型的,可能是文本型的,也可能是字典或者列表。半结构化数据,属于同一类实体可以有不同的属性,即使他们被组合在一起,这些属性的顺序并不重要。
- 非结构化数据(unstructured data):没有固定结构的数据,如OFFICE文档、文本、图片、图像和音频、视频信息等等。一般直接整体进行存储,且存储为二进制的数据格式。
近年来,随着互联网应用的加速普及,产生于移动终端、社交媒体和传感器等不同来源的数据量快速上升,这些具有海量增长(Volume)、异构多源(Variety)、实时高频(Velocity)特征的数据给传统的数据内涵认知带来了新的挑战,为此,近年来欧美学术界提出了数据化(datafication)的新观点,进一步拓展了数据的认知内涵与外延。
这一观点认为,数据化是信息技术驱动的意义建构(sense-making)过程,它包括三个关键机制,分别是去物质化(dematerialization)、流动化(liquification)和稠密化(density),如图 1.1 所示:
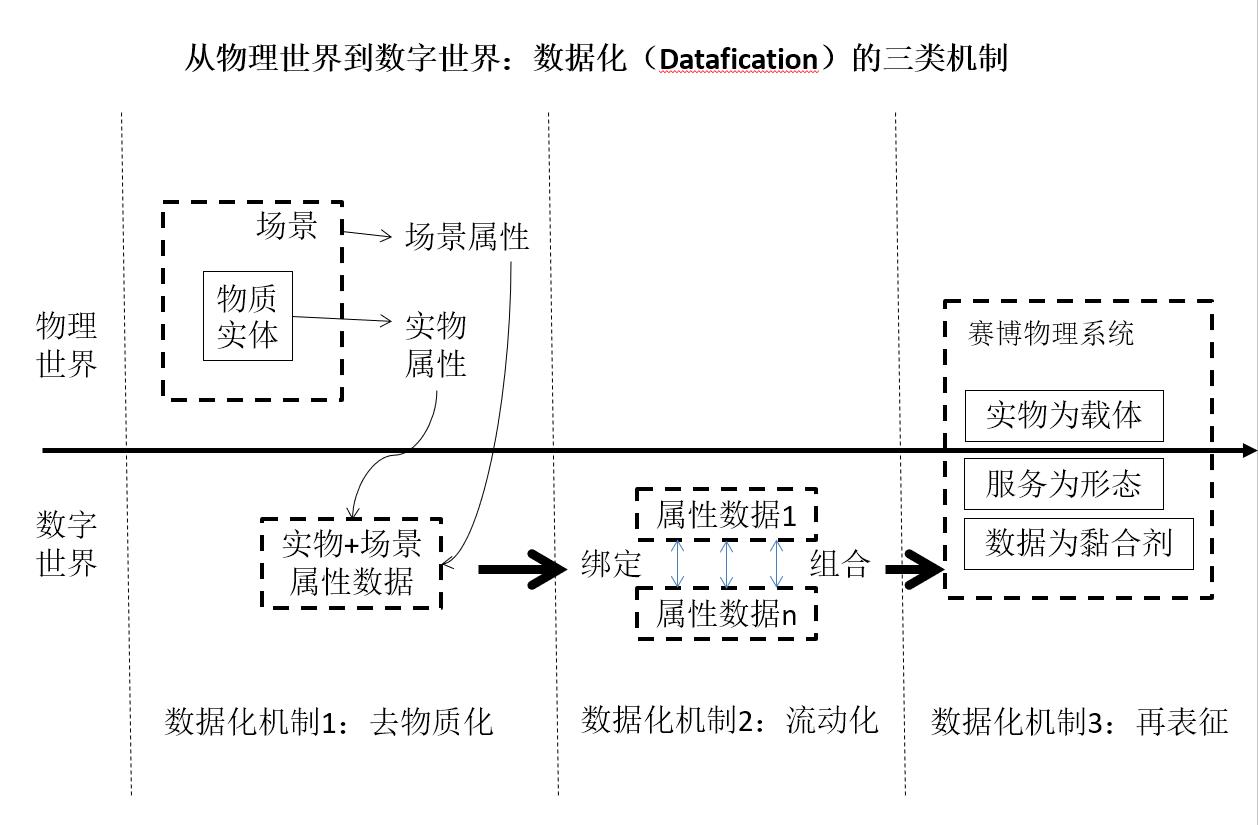
图 1.1: 数据化的三种机制
去物质化是将物理世界的资源或资产及其使用场景的信息属性与对应的实体分离。流动化是指去物质化后的数据或信息通过捆绑、组合及迁移生成新的数据或信息资源,它们能够基于适当的IT基础设施自由流动。稠密化是数据或信息流动形成的特定场景下的资源最优组合,是价值创造过程的产物(Lycett 2013),也是基于数据的新价值创造形式(Marjanovic and Cecez-Kecmanovic 2017)。
以美国奈非(Netflix)公司的流媒体(streaming)业务为实例:奈非公司视频内容(资产)和用户租看(用户偏好)数据的分离,可视作数据的去物质化;个性化的视频内容推荐,反映的是用户偏好数据与视频内容的重组,体现为数据的流动化;基于多年的用户视频行为和偏好数据奈非公司开始自制满足大众偏好的原创内容(纸牌屋等畅销剧),开创出数据驱动的内容定制这一新模式,可以等同为数据的稠密化。
1.1.2 信息的概念、特征与度量
1.1.2.1 信息的内涵与特征
国际标准化组织(ISO)将信息定义为“对人有用、能够影响人们行为的数据”,在中国的GB5271.1-85标准的“01.01.02信息”款下,信息被定义为“人们根据表示数据所用协定而赋予数据的意义”。根据上述定义,信息有以下几点主要特征:
传载性 信息的传载性是指信息可以传递,并且在传递中必须依附于某种载体。通常,语言、文字、声音、图像等都是信息的载体,用于承载语言、文字、声音、图像的物质也是信息的载体。
例如,我们通过电视、电脑、移动终端等看新闻,声音、图像是信息的载体,电视机也是信息的载体。共享性
共享性是区别于物质和能量的一个重要特征,信息的共享不仅不会产生损耗,而且还可以广泛地传播和扩散,使更多的人共享。例如,老师上课就是一个信息共享的过程。可处理性
信息可以被加工、传输、存储,特别是经过人的分析、综合和提炼等加工,可以增加它的使用价值。时效性
只有既准确又及时的信息才有价值。一旦过时,就会变成无效的信息。
案例:
在《信息简史》一书中,描写了非洲本地土著居民传递信息的很好实例。
鼓是非洲十分普遍的乐器,除了音乐节奏功能外,还被用来传递各种信息,成为不同村庄、部落的人们信息沟通的重要工具。人们将敲击鼓音的高低、音调的变化赋予了不同的含义。为确保同音多义词的正确理解,还引入上下文信息冗余来克服可能出现的歧义问题,例如,传递信息“那俯览大地的月亮”和“那啾啾叫的小鸡”就可以区分同音词是传递月亮还是鸡的含义。从上述案例中,我们至少可以得到以下两点启示:
信息的产生、传输与应用可以借助多种工具载体实现。案例中,鼓是信源,声波是信息的载体,空气是信道,人的耳朵是信息的接收器(信宿),大脑是信息的解析器。不同的人类社群在不同的发展阶段往往依赖不同的信源载体。
信息需要按照事先约定俗成的规则来编码、解码。信息传递(通信)技术的发展主要体现在信息的编码、传输和解码技术的进步上,单位承载信息密度更高,传输速率更快是通信技术不断发展的动力。
1.1.2.2 信息与数据的进一步比较
- 信息不依赖于数据存在。
用绳结记录和传输信息的方法在世界范围内通行,“上古结绳而治”,大事记个大结,小事记个小结。人类的语言和文字并不相同,但信息指向可以一致。计算机科学产生于20世纪中期,在计算机系统中,数据以二进制信息单元0,1的形式表示。和结绳记事相比,0和1要传达的信息必须通过机器才能解读。
- 机器不可读的信息不是数据。
言语、眼神和动作可以表达爱慕与憎恶,但不被机器捕捉到的语音、虹膜与体态则不会转化为数据;记录或者刻画在纸张竹简或者龟壳兽骨上的文字可以传达信息,但不被直接录入机器或者拍摄为图像视频存储就不属于结构化或者非结构化数据。
- 同样的数据可以传达不同的信息。
听到同一句话,不同的人有不一样的感受,获得的信息并不相同。机器对自然语言或者人脸传达的信息进行处理,努力获得人类真实意图甚至挖掘潜意识,可以分辨出学生走神或者面试者的紧张。机器解读数据,像人一样看见、听见、感知甚至思考,人与人之间也许不再有误解;通过对个人画像从而定向推送商品或者服务,市场中信息最终可以“对称”。
4.数据可能被损毁或者删除,但信息可以长存。
数据并非记录信息的唯一途径方式,口口相传或者用人脑记住的信息并不依赖数据甚至传统记录方式为载体。人类习惯生活于受时间与知识量等制约的人脑记忆中,机器可以永久留存信息让人不安,因此法律赋予了个体要求对信息更正和删除的权利,甚至可以要求对公开和准确真实的信息从网络“擦除”,希望在网络世界被遗忘。
5.数据是信息的载体,信息价值由数据承载。
越来越多的信息沉淀于网络之中,以数据形式被记录。信息是无形的,数据可以触碰。数据本身是无意义的电子符号,其价值由其传达的信息能够给数据主体带来的收益所决定。
1.1.2.3 信息的度量——信息熵
信息如何度量呢?一个直觉的定义如下:
信息量等于传输该信息所用的代价
两个相同的信源所产生的信息量两倍于单个信源的信息量
但是,直觉的定义立即会引起置疑:
一卡车Beatles的单曲CD盘,承载的信息量很大吗?
“很高兴见到你”,“平安到达”,“生日快乐”,“妈妈,母亲节快乐!”
电文传达的信息与其长度等效吗?
天气预报消息量
夏天预报下雪和冬天预报下雪,哪个消息含有更大信息量?
为解决上述问题,信息量的度量引入了信息熵(entropy)这一数学物理概念。
信息论之父 C. E. Shannon 在 1948年发表的论文“通信的数学理论( A Mathematical Theory of Communication)”中指出:一条信息的信息量大小和他的不确定性有直接的关系。信息中排除了冗余后的平均信息量称为“信息熵”,相应的数学表达式如下:

图 1.2: 信息熵
上式中,H(X)代表的是随机事件构成的系统,-logp(x)代表是某离散随机事件的自信息,其定义如下:

图 1.3: logp(x)
下面我们通过几个示例来进一步了解信息熵:



图 1.4: 关于信息熵的几个计算示例
问题:
英文的信息熵如何计算?(请按照26个字母加一个空格符计算)结果是多少?汉字作为一个复杂的象形文字符号系统,其信息熵很高,随着汉字容量增大,信息熵的增加趋缓;汉字增加到12370以后,不再使信息熵有明显的增加。我国科学家指出:汉字的容量极限是12366个汉字,是世界上信息量最大的文字符号系统。
根据科学家们的测算,联合国五种工作语言文字的信息熵分别为:法文:3.98比特;西班牙文:4.01比特;英文:4.03比特;俄文:4.35比特;中文:9.65比特。这反映出信息熵越高,语言越言简意赅;信息熵越低,语言越冗余堆积的特点,但另一方面,作为符号编码代表的中文,信息熵很高,在计算机编码中,单位存储空间占用的字节数也较多。
1.1.3 知识的概念及分类
知识是指人类迄今为止通过思考、研究和实践所获得的对世界(包括物质世界和精神世界)认识的总和。在GB/T23703.2-2010中的定义–知识是通过学习、实践或探索所获得的认识、判断或技能。
知识可以分为显性知识(explicit knowledge)、含蓄知识(tacit knowledge)与隐性知识(implicit knowledge)。
显性知识(explicit knowledge)指的是可以被编码和转化为系统的正式语言,如:文件,数据库,网络,电子邮件,图表等。一般而言,人类的知识大多以显性知识的形态传承下来。
含蓄知识(tacit knowledge)指的是个性化的,有具体目的,不能记录但能表达的知识,如群体的潜规则等。含蓄知识的交流、共享与情境密切相关.含蓄知识的共享实质上是一个知识创造的过程,只有亲临现场、共同在场、互动沟通,才能有效地传递与分享含蓄知识,并基于此创造知识.
隐性知识(implicit knowledge)指的是不能记录也无法表达,隐藏在人的头脑中的智慧,它主要通过在实践中不断总结、感悟而获取,所谓“师傅带进门,修行靠个人”。
1.1.4 数据-信息-知识-智慧之间的区别与联系
数据是对客观事物的一种反映,如数据3.14,在没有任何加工处理之下,只是一个单纯的数字而已。而信息是加工处理过的数据,是客观世界的客观反映,是对接收者有意义的数据;如在一定条件下,经过加工处理,3.14表示圆周率。知识是经过提炼有价值的信息,如可以利用圆周率计算周长、面积等。
智慧不是知识,一个人知识多并不代表着有足够的智慧,有些人没有太多知识但在某些方面却能成为奇才;智慧也不同于聪明,聪明的人拥有智慧但不能说愚笨的人没有智慧,正所谓大智若愚,这些人虽然看起来愚笨,不露锋芒,但是他们才是真正的智者。智慧是人类所表现出来的独有的能力,并不是单纯的知识,它是在知识的基础上总结原理和法则,来解决难以解决的问题,是一种运筹能力。数据-信息-知识-智慧的层级关系如图 1.5:
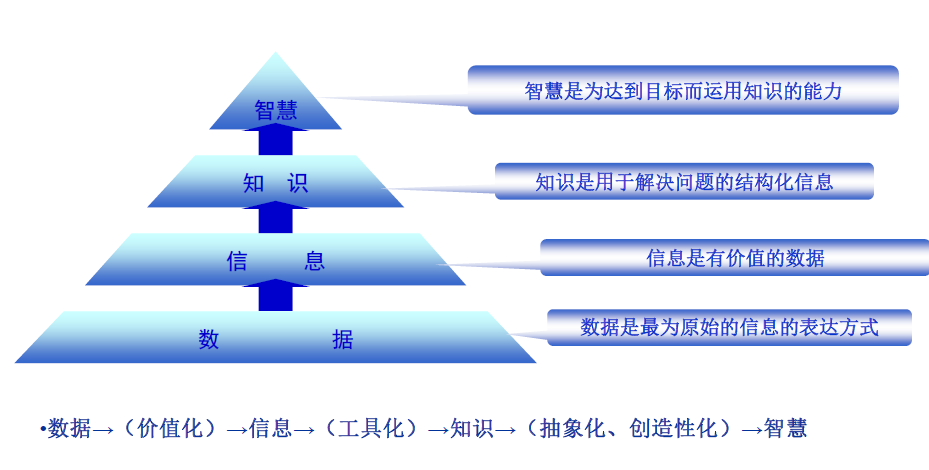
图 1.5: 数据-信息-知识-智慧层级关系