4.2 用户需求及体验分析
4.2.1 用户需求分析的目的
用户需求分析的目的主要包括以下几方面:
谁是信息系统的用户?
这些用户何时、何地以何种方式完成现有的任务?
用户在现有实践中感知到的问题痛点是什么?
用户在现有实践中期望改进的问题排序有哪些?
思考问题: 如果你是微信的初始研发团队成员,准备开展微信的需求分析,请回答:(1)谁是微信的潜在用户?(2)这些用户通常以何种方式,何种场景开展及时通信联系?(3)用户在使用IM软件过程中,是否存在痛点?这些痛点是什么?(4)识别的用户痛点重要性和紧迫程度排序怎样?
4.2.2 用户需求分析的对象
需求分析涉及的用户类别主要有:
主要用户 (primary stakeholder):也称为终端用户,是直接使用系统的用户。(如使用北邮教务系统的学生)
次要用户(secondary stakeholder):没有直接使用系统,但间接使用,如获得系统的某些输出结果。 (如看北邮教务系统输出报表的校长)
第三类用户(tertiary stakeholder):没有使用系统,但直接受到系统的正面或负面的影响。 (没有使用北邮教务系统,但总听到学生抱怨的辅导员老师)
思考问题: 如果你是微信的初始研发团队成员,请举例指出微信的三类用户。
4.2.3 用户需求分析的数据类别
要了解用户的需求,需要采集反映用户使用行为的数据,有两类:
- 定量数据(quantitative data):可以转成数值型数据的用户行为信息。例如通过微博、微信采集的用户评论、用户博文等各类用户生成内容(User gerated content, UGC)即属于定量数据范畴,根据用户属性(如性别、年龄、地区等)与用户生成内容分析用户偏好、用户的行为动向等即属于定量数据分析。在用户需求分析中常用的一种方法是用户画像(Persona)。
用户画像这一概念最早源于交互设计-产品设计领域。交互设计之父 Alan copper 较早提出用户画像(persona)概念,指出用户画像是真实用户的虚拟代表,是建立在真实数据之上的目标用户模型。在交互设计-产品设计领域,通常将用户画像界定为针对产品-服务目标群体真实特征的勾勒,是一种勾画目标客户、联系客户诉求与设计方向的有效工具,借助用户画像手段,设计师将头脑中的主观想象具化为目标用户的轮廓特征,进而构造出设计原型或产品原型。
近年来,随着互联网行业的蓬勃发展,为解决产品运营中的用户定位不精准、用户运营中的个性化服务不足问题,将用户画像引入用户行为分析,通过对用户打标签、建立数据模型来解读”全样本”用户的行为特征开始成为互联网产品设计及运营的趋势。具体而言,在互联网用户行为分析领域,用户画像被概述为用户信息标签化,通过收集与分析用户的社会属性、生活习惯、消费行为等数据,抽象出一个虚拟用户的特征全貌,不仅帮助企业全方位、多视角地了解用户行为特征,把握用户行为动向,还可以帮助企业针对细分用户开展产品个性化精准设计、定制、营销和服务。
从交互设计-产品设计转向用户行为分析,用户画像的内涵及外延一直在动态变化中。在互联网应用领域,用户画像主要指以真实用户群体为对象,以用户的静态属性(人口统计特征、空间和地理特征等)和动态属性(消费行为、使用行为等)数据为基础,通过定性或定量方法提炼抽象出的具有显著特征的用户模型。
用户画像的内涵具有以下几个特点:
首先,用户画像是真实用户的虚拟代表。用户画像对象不是单个用户,而是特定用户群体。具有相似文化、经济、教育等背景的用户群在使用产品-服务时呈现出相似的共同特征,这就构成了用户画像的基础。用户画像的目的是通过对特定行为群体特征的总结和提炼,为产品-服务个性化设计、营销提供量化支撑。因此,用户画像对目标用户群体边界界定越明确,画像结果越有针对性。
其次,用户画像结果是有显著特征的用户模型。用户画像关注的是”典型用户”,不是”平均用户”,其有效性体现在对目标用户群体的静态和动态属性特征的提炼与总结。用户画像提炼的群体用户特征具有明显区隔性和对象针对性,可以更精准地识别特定用户的动机及行为偏好,进而为新产品设计、已有产品改进指明方向。
最后,用户画像强调以用户为中心,以用户需求为指引。互联网时代,产品和服务的价值体现在用户的高频使用中,需要根据用户使用产品-服务的场景分析用户的需求,来设计或改进产品-服务。用户画像就是要通过定性定量手段将用户需求”聚焦”——标签化,这些标签以可视化的形式描述了用户的目标、动机,以及与现有或待开发产品之间的联系和使用场景。
用户画像不是静态的快照式描绘,而是从个体到群体,从具体到抽象,从宽泛到聚焦的一个动态过程。用户画像思路从产品为中心转向用户为中心,画像范围从单一用户自身特征向用户所处场景、心理动机和使用行为特征延展,画像手段从纯主观想象到海量数据+算法模型驱动相结合,画像对象也由用户向物理产品、数字化内容、数字化服务等扩展。
典型的用户画像体系(银行业为例)如图 4.2 示意:
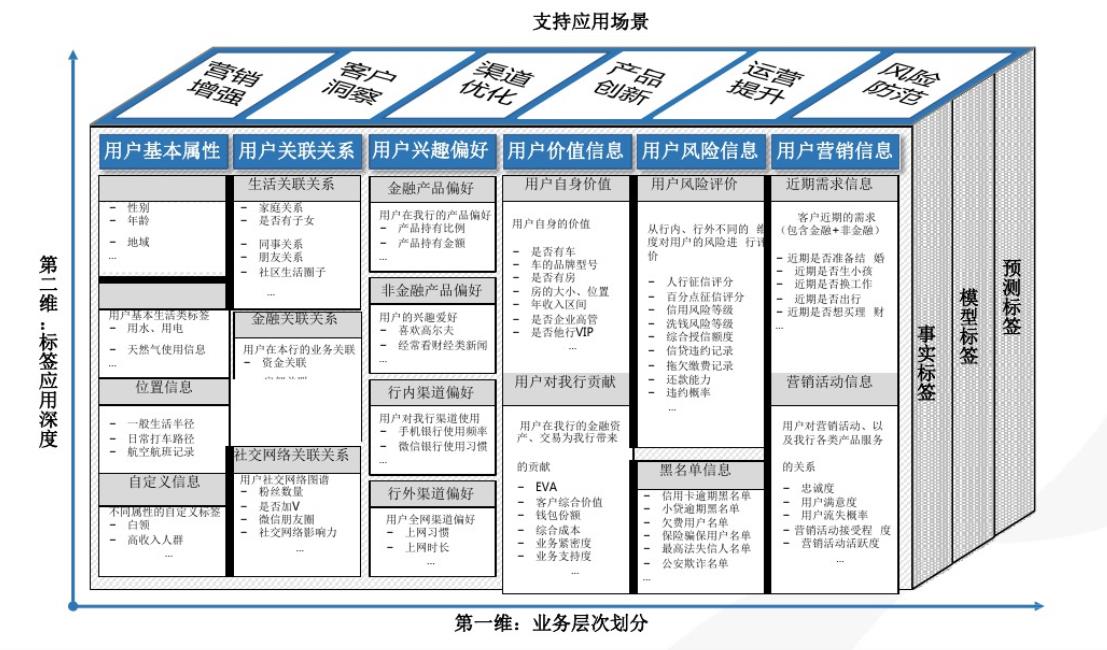
图 4.2: 银行业的用户画像构建体系
关于用户画像方法及应用,更多详情可以查看课件:用户画像概念、方法与应用,或进一步阅读第 4.5 节:用户画像方法与应用 论文。
案例讲解:北京二手房画像—基于Python的数据爬取和数据可视化
背景:
北京二手房情况复杂且动态多变,为给北京二手房画像,拟采集链家平台上的北京二手房数据,全面了解北京二手房交易情况。
工具:
使用 python 中的以下第三方库采集数据,完成数据的可视化
- pandas # 数据分析
- re # 正则表达式处理文本字符
- requests # 网络请求
- json # 数据键值对存储格式
- pyecharts # 数据可视化
- folium
- random # 生成随机数
- stylecloud # 绘制词云图
- jieba # 中文分词
- pyquery
- fake_useragent # 伪装代理访问
- time # 设置爬数据间隔
数据采集
所有数据来源于链家二手房交易平台,如图 4.3示:每页排列 30 条二手房数据,可以采集前 100 页数据,每条二手房交易数据中提取标题、单价、价格、地址、年份、房间样式 等字段作为可视化分析的数据基础。
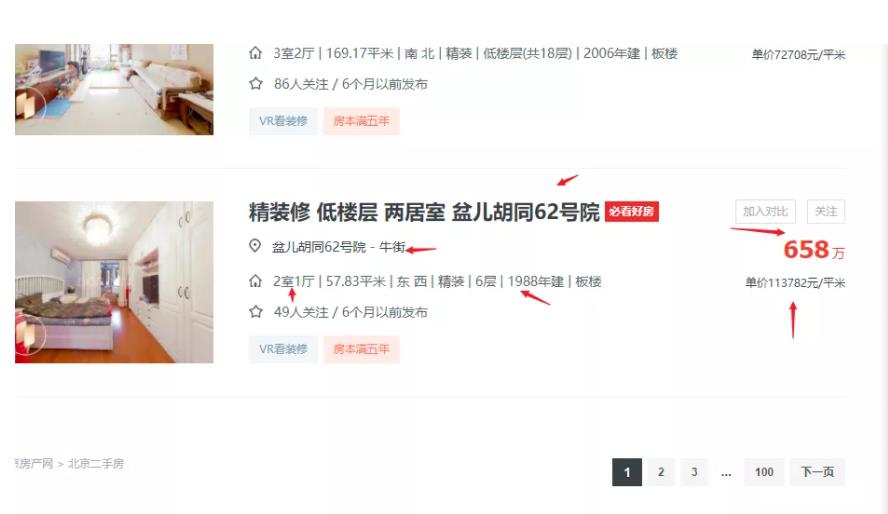
图 4.3: 链家二手房数据爬取页面示意
网站没有设置很强的反爬机制, 爬取时用的是 requests + Cookies+ PyQuery 组合即可,最好在爬取时加条 time.sleep() 命令,隔几秒休眠一次,数据爬取部分示例代码如下:
import requests
from pyquery import PyQuery as pq
from fake_useragent import UserAgent
import time
import random
import pandas as pd
UA = UserAgent()
headers = {
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cookie': '你的Cookie',
'Host': 'bj.lianjia.com',
'Referer': 'https://bj.lianjia.com/ershoufang/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36',
}
num_page = 2
class Lianjia_Crawer:
def __init__(self,txt_path):
super(Lianjia_Crawer,self).__init__()
self.file = str(txt_path)
self.df = pd.DataFrame(columns = ['title','community','citydirct','houseinfo','dateinfo','taglist','totalprice','unitprice'])
def run(self):
'''启动脚本'''
for i in range(100):
url = "https://bj.lianjia.com/ershoufang/pg{}/".format(str(i))
self.parse_url(url)
time.sleep(random.randint(2,5))
print('正在爬取的 url 为 {}'.format(url))
print('爬取完毕!!!!!!!!!!!!!!')
self.df.to_csv(self.file,encoding='utf-8')
def parse_url(self,url):
headers['User-Agent'] = UA.chrome
res = requests.get(url, headers=headers)
doc = pq(res.text)
for i in doc('.clear.LOGCLICKDATA .info.clear'):
try:
pq_i = pq(i)
title = pq_i('.title').text().replace('必看好房', '')
Community = pq_i('.flood .positionInfo a').text()
HouseInfo = pq_i('.address .houseInfo').text()
DateInfo = pq_i('.followInfo').text()
TagList = pq_i('.tag').text()
TotalPrice = pq_i('.priceInfo .totalPrice').text()
UnitPrice = pq_i('.priceInfo .unitPrice').text()
CityDirct = str(Community).split(' ')[-1]
Community = str(Community).split(' ')[0]
data_dict ={
'title':title,
'community':Community,
'citydirct':CityDirct,
'houseinfo':HouseInfo,
'dateinfo':DateInfo,
'taglist':TagList,
'totalprice':TotalPrice,
'unitprice':UnitPrice
}
print(Community,CityDirct)
self.df = self.df.append(data_dict,ignore_index=True)
#self.file.write(','.join([title, Community, CityDirct, HouseInfo, DateInfo, TagList, TotalPrice, UnitPrice]))
print([title, Community, CityDirct, HouseInfo, DateInfo, TagList, TotalPrice, UnitPrice])
except Exception as e:
print(e)
print("索引提取失败,请重试!!!!!!!!!!!!!")
if __name__ =="__main__":
txt_path = "ershoufang_lianjia.csv"
Crawer = Lianjia_Crawer(txt_path)
Crawer.run() # 启动爬虫脚本 使用 Pyechart 可视化数据分析输出典型图表如下:
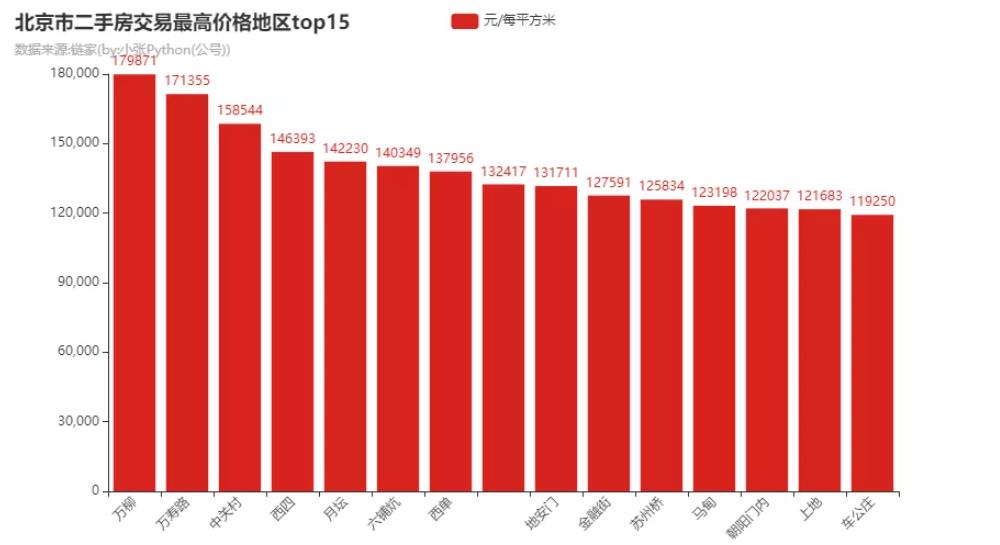
图 4.4: 北京二手房可视化输出
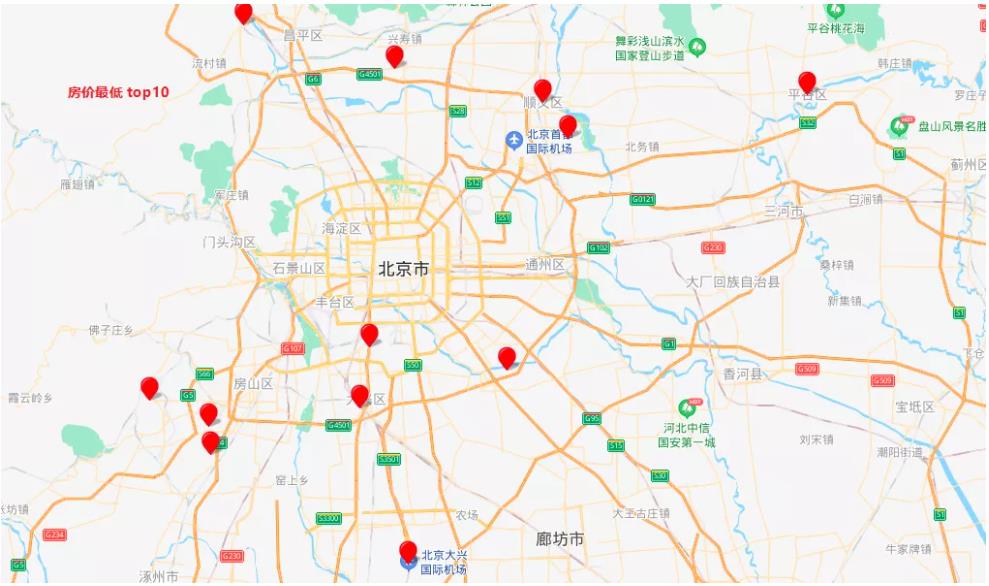
图 4.5: 北京二手房可视化输出
- 定性数据(qualitative data):反映用户行为的主题信息(thematic information),定性数据多以文本数据为载体,在分析方法上常以手工编码的方式对文本数据反映的语义特征进行编码,然后再做分析。例如,在回收用户问卷中的开放式问题后,对回复结果进行编码,根据编码结果再行统计分析,这就是定性数据分析。
定量数据可以帮助告知用户行为是什么(what),定性数据可以帮助告知用户行为为什么(why)
常用的定量数据分析工具软件有 SPP、SAS、STATA等,常用的定性数据分析工具软件有 Nvivo(可以访问公司官网:https://www.qsrinternational.com/ 进一步了解)等。随着开源数据分析工具的快速发展,以R、Python为代表的脚本式编程软件已能完成定量与定性分析的双重任务,因此,未来掌握以R、Python为代表的编程软件不仅是数据分析师的基本技能要求,也是开展量化需求工程(Quantitative requirement engineering)的基础。
4.2.4 搜集用户需求的常见方法
常见的用户需求搜集方法有四种:自然观察(naturalistic observation)、问卷(survey)、焦点小组(focus group)和访谈(interview)法。这四种方法可以从两个维度来考察,一个维度是与用户的交互程度,很明显,自然观察法更加强调从旁观者视角去考察用户的真实行为状态,基本不涉及与用户的互动,因此交互程度最低,而访谈法通常是一对一的互动交流,与用户的交互程度最高。相对而言,问卷法和焦点小组法介乎其中。另一个维度是该方法的使用场所,是现场采集还是离场采集。自然观察法通常需要在现场观察,而另外三种方法可以不在系统使用现场采集需求,可以坐在办公室里召集典型用户来搜集。
在需求搜集过程中,可以按照先自然观察,再发放问卷,进而开展焦点小组讨论,最后一对一访谈的方式将用户需求由粗到细,由浅而深,由轮廓再具体地形成。
- 自然观察法
自然观察法通常是分析人员去信息系统的使用现场,通过观察主要用户或次要用户的行为,以定性(文字描述或拍照记录)或定量(使用时长、频次等)方式采集用户数据。该方法的优点在于没有干扰用户的使用,能够较为真实地获取用户;缺点主要是由于没有与用户的交互,采集的数据无法进一步了解,用户行为背后的深层动因。因此,这一方法,往往用于需求搜集的早期,让分析人员对用户行为有整体的概要认识。
- 问卷法
问卷法是用书面形式间接搜集资料的调查方式,它针对需调查的各项内容,编制详细问卷,对各类用户进行全面的需求填表调研,然后借助统计分析手段整理得出所要调查的内容。运用问卷调查法时应该提高问卷的质量,注意封闭型问题(如选择题)和开放型问题(问答题)的合理设置。该方法的优点在于能够较为集中地获取批量用户的需求,缺点是缺乏与受访用户的交互。问卷法可以在自然观察法的基础上展开。互联网应用的快速普及使得问卷发放与回收日趋在线化,利用开源免费的在线问卷工具搜集问卷成为市场研究人员、科研人员快速了解众多用户需求的重要途径。
常用的在线问卷工具有 问卷星 、 问卷网、腾讯微信小程序——腾讯问卷等,这些工具软件大都上手容易、操作简便,在用户需求调研分析时可选择使用。
- 焦点小组法
焦点小组法是召集5-10位关键用户,以座谈会的形式来帮助分析人员一次性获取多位用户的需求,或对焦点问题的看法。这种方法可以在问卷法之后使用,便于将问卷中未能揭示或反映的问题,通过座谈方式得以深度交互了解。这种方法的缺点体现在两方面:其一,由于参与人较多,要求座谈会的主持人水平较高,能够对讨论议题、讨论时间较好把控;其二,座谈中可能出现部分人讨论积极,另部分人较为沉默的情况,使得座谈的成效打上折扣。
- 访谈法
访谈法首先需要根据用户需求搜集的目的和任务要求,编制访谈提纲,然后选择适当的典型用户进行访谈,并分类整理结果,从而较为全面而又具体地了解不同类型用户对系统的共性和一般需求。其中,访谈提纲包括访谈背景介绍、访谈目的、访谈问题和资料准备;在访谈的过程中需要做好录音以此记录访谈内容,同时还要设计思维导图进行要点梳理。访谈法是对关键用户个性化需求的深度了解,由于规避了其他人的干扰,往往能获知访谈对象的真实想法,不过缺点是费时费力,周期较长。
这四种方法在实际中的应用至少要注意两点:
首先,鉴于需求的搜集和分析是一个由粗及细的过程,根据上面对四种方法的介绍,可以序采用自然观察法、问卷法、焦点小组法和访谈法,使得每种方法获取的用户需求信息可以在一定程度上相互应证,从而为需求优先级确定提供充分的参考依据。
其次,不同业务特点的信息系统在使用上述方法时也有一定的经验可资借鉴:针对企业中的流程型信息系统(如ERP、CRM、SCM、财务系统等)较多的采用自然观察法、访谈法两种方式;对于分析型的信息系统(如经营分析系统、商业智能系统)较多的采用问卷法、焦点小组法和访谈法。随着人员需求发生变化,可以选择几位典型代表做焦点小组访谈,快速获取用户个性化需求,若了解还不够可通过问卷调查补充用户的共性需求。
案例讲解:如何将人工智能(AI)技术与企业报销流程相结合?
企业中的典型报销流程(包括线上系统流程与线下人工流程)可以描述如下:
- 发起申请:报销人发起申请后,需要自行对出差报销票据做出整理,对票据进行分类,并计算出各个类别所对应的金额(如出行,住宿);
- 填写表单:报销人把各类需要报销的费用填写到线上报销系统的表单上并在线提交表单;
- 递交票据:报销人线下递交票据给财务前台;
- 财务审核:财务前台人工核对线下提交的票据与线上提交表单内容是否一致;
- 审核结果:报销系统展示审核通过与否。
对上述报销流程拆分后,可以知道每个环节都需要进行哪些操作,然后对现有的人工智能技术进行筛选和评估,找出可以替代人工操作的环节,从而实现产品的智能化驱动,流程分析步骤如图 4.6 示意:
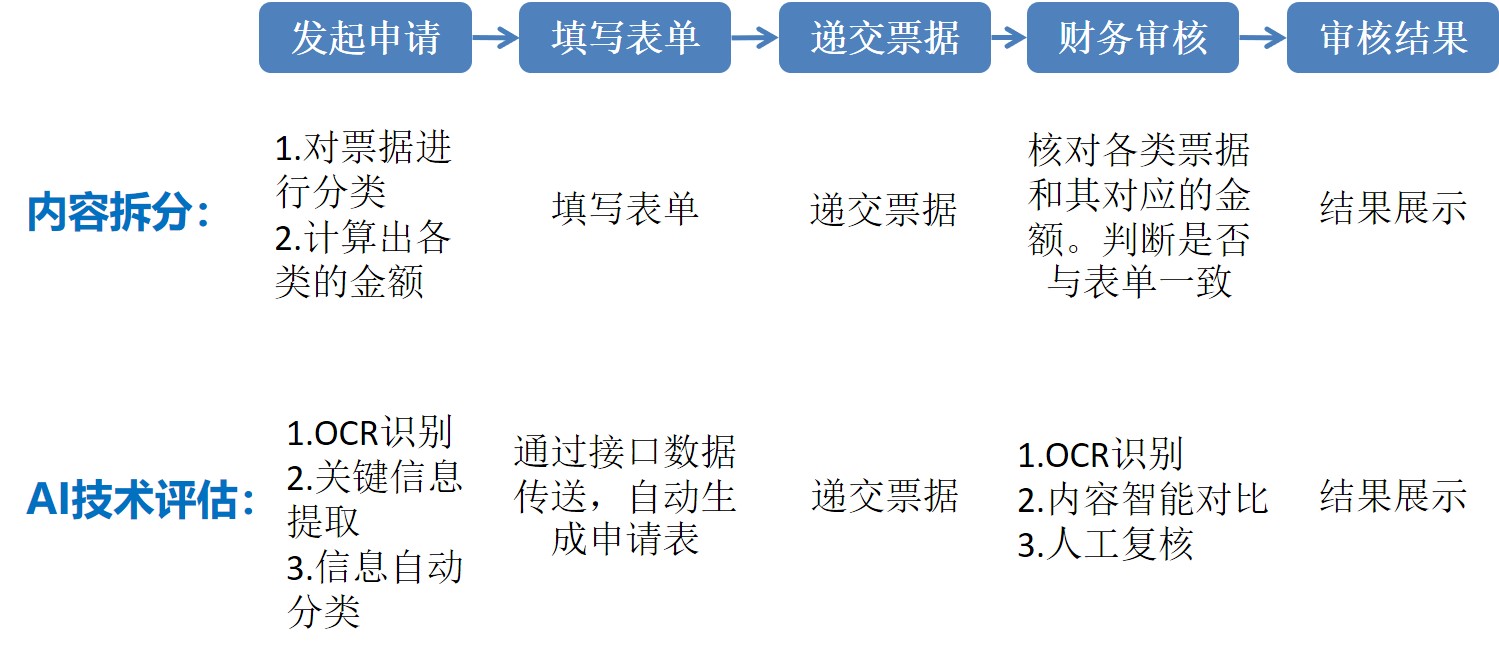
图 4.6: 报销流程分解与AI技术评估
找出能够代替人工操作的AI技术后,需要用大量的数据,对这个AI模型进行训练,使得用AI处理的报销单通过与否的准确率更高,相应的技术应用评估如图 4.7 示意:
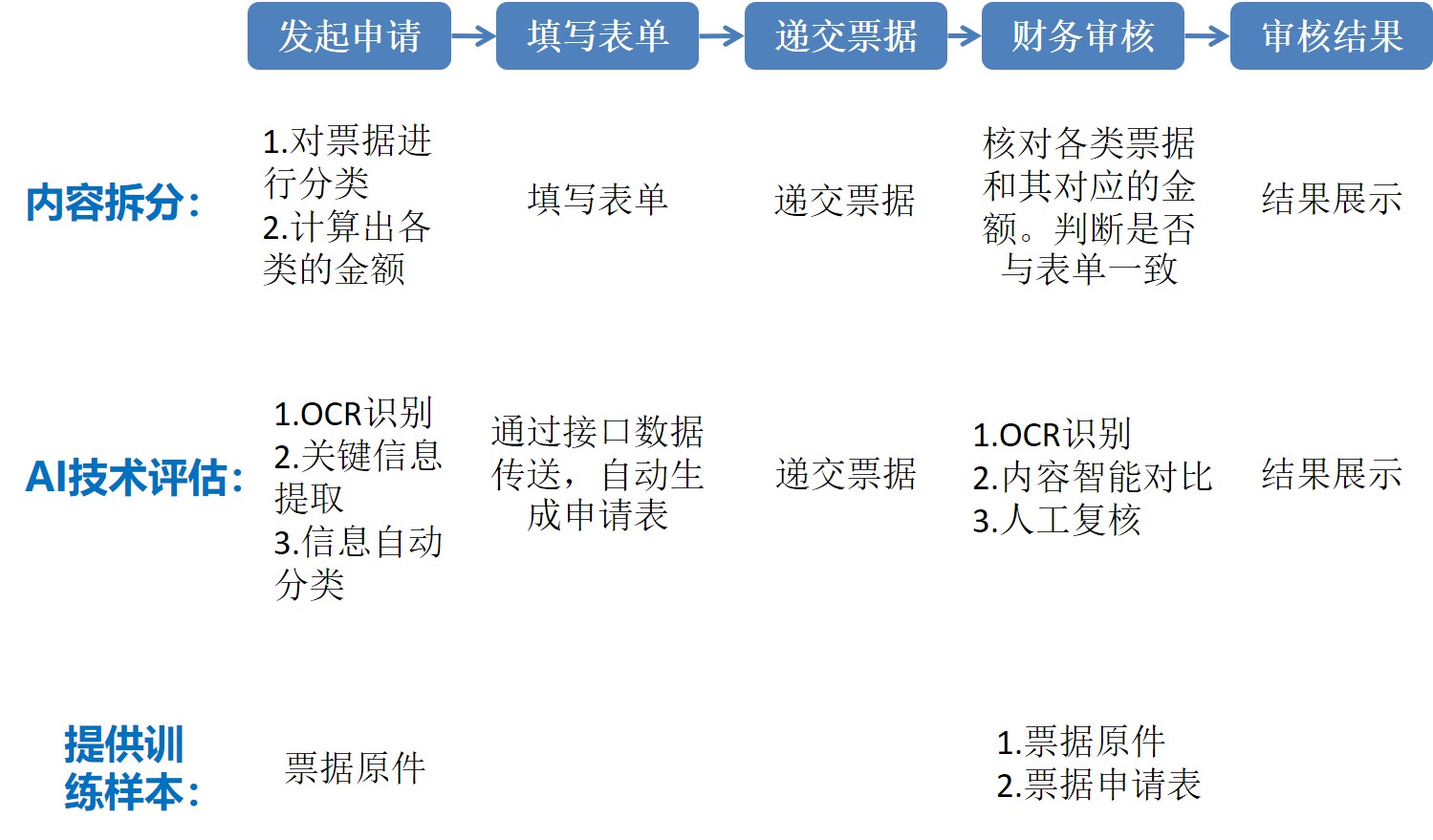
图 4.7: 报销流程分解与AI应用评估
至此,AI技术驱动并优化的报销流程及对应的报销系统需求就明确下来了。
案例要点小节:
- 流程拆解:首先要对现有的报销流程进行拆解,诊断出能够提升生产效率的关键环节并进行优化,从而达到提升效率的目的;
- AI评估:对AI技术要有了解,能够识别出对当前业务优化或改进有积极影响的AI技术;
- 技术需求分析:完善基础数据,进行模型的预分析,并测试;
- 整合需求分析:将验证后的技术分析结果导入实施方案,明确AI驱动的报销系统详细需求。
来源:微信公众号 人人都是产品经理 2018-11-29
4.2.5 用户体验分析
什么是用户体验?
广义而言,用户体验是指用户在使用某项产品/服务之前对其的预期,使用该项产品/服务过程中的心理感受,以及使用后对该产品/服务形成的印象。
具体到信息系统分析与设计的情境,用户体验主要指用户在使用应用软件过程中,对其I/O交互,功能及性能的心理感受。
用户体验分析是为了更好地增强用户对软件的体验感受而对已有软件或类似软件进行分析,以识别缺陷或潜在问题,从而形成满足用户痛点需求的过程。
在用户体验分析中常用到的一种方法和工具是用户体验历程图(User Experience Journey Map, UXJM),这是以用户使用某个产品或体验某项服务的全过程为背景,找出用户与产品/服务交互的每个触点(touch point)可能存在的问题,进而优化改进的一种方法、工具。用户体验历程图主要有三大用途,首先,可以帮助系统分析人员了解用户的需求和期望,以及用户如何使用产品,有哪些典型的行为;其次,将用户对使用产品的体验流程以可视化图表呈现,方便研讨;第三,将图表上的各个分散的点连成线,讲诉一个用户体验故事,让分析人员有极强的场景感受。
用户体验历程图的绘制步骤可以分为以下6步骤:
步骤1:选择一种典型用户角色
针对每种典型用户角色或是每一类用户群体往往可能能够绘制出不同的用户体验历程图,因此通常首先会选择一种典型用户角色,绘制这种典型用户角色的历程图,然后再寻找不同典型用户角色之间的重复部分进行整合合并。
步骤2:确定不同用户体验阶段
明确典型用户角色和产品/服务的主要触点,以及交互时所形成的主要阶段划分。例:一个用户购买笔记本电脑等消费类电子产品时形成的主要用户体验阶段可以划分如图 4.8 所示。

图 4.8: 用户体验阶段
步骤3:定义用户体验步骤
相比用户体验阶段,用户体验步骤更加具体,是用户在某一个特定的用户体验阶段中所经历的体验动作(action)。
例:用户在考虑购买一台新的笔记本电脑时可能会经历的用户体验步骤如图 4.9 示意。

图 4.9: 用户体验步骤
步骤4:明确用户与产品/服务的接触点
接触点是指用户和产品/服务互动时的有形/无形交互媒介,既包括线下渠道的触点,也包括线上渠道的触点。
步骤5:绘制用户体验历程
以用户触点为中心,采用问卷、访谈等多种方式,获取关键用户的产品/服务体验历程信息,进而绘制出用户体验历程。
例:壁挂图方式手动绘制的用户体验行为历程如图 4.10 所示:


图 4.10: 用户体验行为历程
步骤6:绘制用户情感波动历程
把搜集到的“问题”和“惊喜”放到对应的每个行为节点上。惊喜点放在上面,问题点放在下面。
示例:壁挂图方式手动绘制的用户体验行为历程

图 4.11: 用户体验行为历程
经过以上6个步骤绘制(示例用手工完成,实际也可以用VISIO、思维导图等软件辅助)完成的用户体验历程图可以与之前完成的用户需求搜集整合在一起,共同构成用户需求分析的阶段成果,为接下来的应用软件功能分析奠定基础。
案例讲解:手机应用FaceU 的用户体验分析,请下载附件 产品用户体验分析-FaceU激萌 (2015级信管学生课程作业),借鉴其思路,从以下两个选题中任选其一,以小组为单位完成课程作业。
作业要求:
- 以常用的某款手机APP应用为对象,借鉴讲解案例的分析思路,绘制该APP应用的用户体验历程图,指出应用亟待解决的需求痛点问题;
- 以身边的某类服务(例如北邮漫咖啡)为对象,通过小组成员的亲身经历与体验,绘制该服务的用户体验历程图,指出服务存在的不足与改进方向;